
Kubernetes (K8s) has become the de facto operating system of the cloud, orchestrating software workloads across clusters of servers. Most GPU-accelerated workflows naturally end up being built on Kubernetes, but it has quite a steep learning curve.
Today we'll talk about how to leverage best practices like GitOps in order to have a GPU-enabled Kubernetes cluster up and running in no time. Whether you want to deploy a large language model (LLM) for inference using vllm, or you have your own plans for the hardware, this guide will help you get there.
Every cloud service provider (eg. AWS, Azure, GCP) has their own Kubernetes offering and the first step is to choose which CSP you want to use. For this article we'll use AWS's Elastic Kubernetes Service (EKS) as an example.
We're also going to be using the free and open-source tool cndi for
bootstrapping your cluster so it can be managed from git. Any changes to your
cluster configuration can be made via pull requests, whether they are hardware
changes managed by Terraform or software changes managed
by ArgoCD.
Step 1: Get Cloud Credentials ☁️🔑
First, you'll need to get your cloud credentials. These keys will be used by cndi (specifically Terraform) to provision the hardware infrastructure for your cluster. You can get these keys from your cloud provider's console and you can find specific instructions in the cndi docs here
Step 2: Create a GitHub Personal Access Token 🔐
You'll need a GitHub Personal Access Token to authenticate with GitHub. This
token will be used so that cndi can create a repository for your cluster, and
again later so ArgoCD can manage your cluster by accessing that same repo. You
can create a token at
github.com/settings/tokens
Step 3: Install the gh CLI 📺
To interact with GitHub from the command line, we'll be using the gh CLI tool
from GitHub. The
cndi
CLI will use this tool to create the repository that manages your cluster,
you'll inherit the repo immediately after we create it for you.
You can install the gh CLI from the
GitHub CLI homepage.
Step 4: Install the cndi CLI 🚀
The cndi CLI is a tool that helps you bootstrap your cluster and manage it
from Git. You can install it by following the install instructions
here.
Step 5: Choose your path 🤗?
At this point you should decide if you intend to bring your own workload to accelerate with GPUs or if you'd like to spin up an LLM from huggingface with vllm.
If you want to use vllm to deploy an LLM like Meta's Llama, go to Step 6.
If you want to bring your own workload, you can skip to Step 8.
Step 6: Request Access to a Model on HuggingFace 🦙
HuggingFace has a wide variety of models avaialable
for you to use, the default model in the cndi vllm Template is Meta's Llama.
You can request access to the model at
huggingface.co/meta-llama/Llama-3.2-1B.
Note, if you opt for larger models you may need to increase the size of the
nodes in your cluster later on.
Step 7: Get your HuggingFace API Key 🗝
Now️ that you've been granted access to the model, you'll need to get your API key from the HuggingFace console. You can create a token to access available models at huggingface.co/settings/tokens.
Step 8: Create your Cluster 🚀
As illustrated in the diagram below, cndi will use Terraform to create your cluster in the cloud of your choice, and it will use ArgoCD and SealedSecrets to manage your cluster through Git.
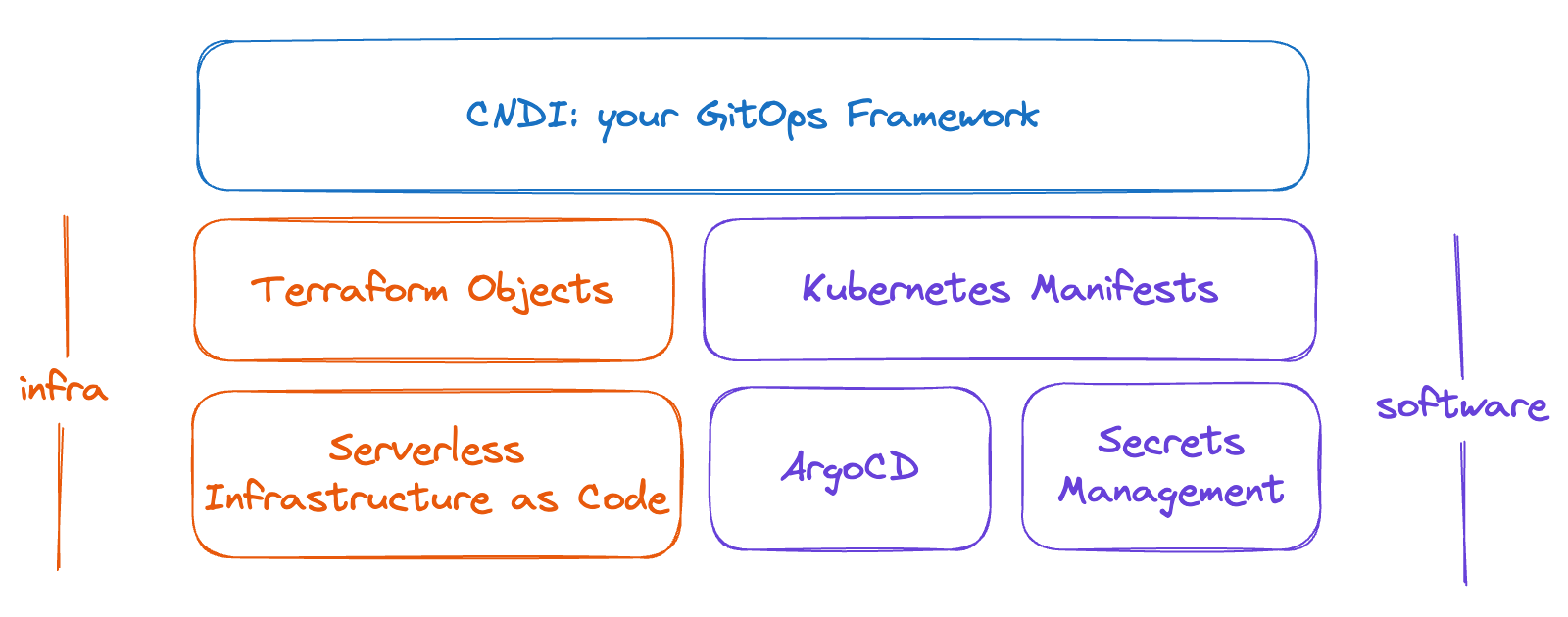
To create your cluster choose a name for the github repo you want to create and run the following command:
cndi create githubuser/my-gpu-cluster && cd my-gpu-clusterThat command will prompt you for a bunch of values, create a repository and then
cd into it after it is published.
If you decided to use vllm you can select that Template when prompted, or you
can select the gpu-operator Template instead if you have other plans.
After you've answered all the prompts, you'll find that cndi has created a repository and configured automation so that any hardware or software changes made to the main branch will be applied to your cluster.
Your cluster will take some time to deploy, but you can follow the progress in the GitHub Actions tab of your new repository.
Step 9: Login to ArgoCD 🔮
ArgoCD is responsible for ensuring that your cluster remains in sync with the contents of your Git repository. If you've specified an Ingress for it and configured ExternalDNS properly, you should be able to see that online shortly after your cluster is up.
Otherwise you can call cndi show-outputs to get the command required to setup
your local .kube/config to access the cluster, and the command to port-forward
ArgoCD will be shown there too. Both require the
kubectl CLI to be installed.
Step 10: Use the GPU! 🔥
Now that your cluster is up and running, if you're using vllm, you can connect to the model service by running the following command:
kubectl port-forward svc/model-service -n vllm 8080:80At that endpoint locally you can send requests to the model service to generate text:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
model: "meta-llama/Llama-3.2-1B-Instruct",
messages: [
{
role: "system",
content: "You are a helpful assistant."
},
{ role: "user", content: "How should I navigate the cloud-native landscape?" }
],
temperature: 0.7
}'If you're using the GPU for another workload, you can use the GPU by ensuring
your workload has the Pod tolerations and node selectors like the example
provided in the gpu-operator Template's cuda-vectoradd example Pod.
Up Next? 👀
In this article we've shown you how to get a GPU-enabled Kubernetes cluster up and running powered by GitOps and Infrastructure-as-Code on whichever cloud you like. cndi has made it quick and easy to get started and brings increased portability, accessibility, and reproducibility to your infrastructure. We hope you enjoy using it as much as we do.
If you'd like us to cover other applications or double down on AI content by looking into technologies like ray.io, or if you have any other feedback please hop into our Discord available in the nav bar at the top of the page!